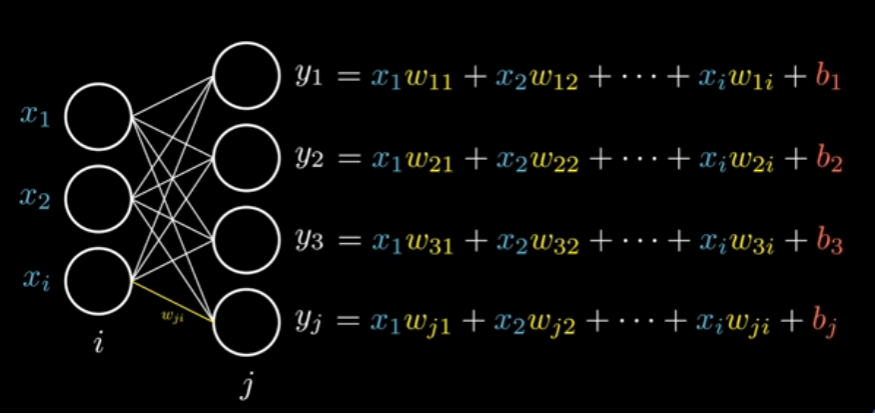
This is actually notes I made while I was just starting to study ML and Deep Learning, I now decided to give them a bit more of use and turning them into a blog post! Maybe my words and way to explain might help someone.
What is a Neural Network?
A Neural Network, in the simplest way possible can be described as a function/formula that is composed by weights and biases (which start random but changes to minimize the loss). A neural network is the basic of any other deep learning model, every model is composed by neural networks, so it is important to know what they are and how they work.
Most of these notes comes from the great creator The Independent Code. So make sure to watch his video for a better review: Neural Network from Scratch | Mathematics & Python Code
Machine Learning Steps:
Let’s first declare how machine learning works and its steps in simple terms:
-
Feed input ⇒ Data flows from layer to layer ⇒ Retrieve output.
-
Calculate the error. (Compare the output with our desired output)
e.g.
-
Adjust the parameters (weight and biases) using gradient descent.
-
Start again
= learning rate hyperparameter
Implementation Design:
Forward Propagation:
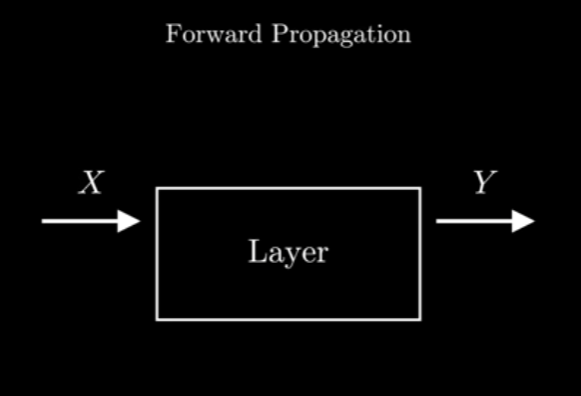
Think it like this, we give (input) to a layer (mysterious box) and all it should do is to give us (output). This “Layer” is, once again, a long equation.
Backward Propagation:
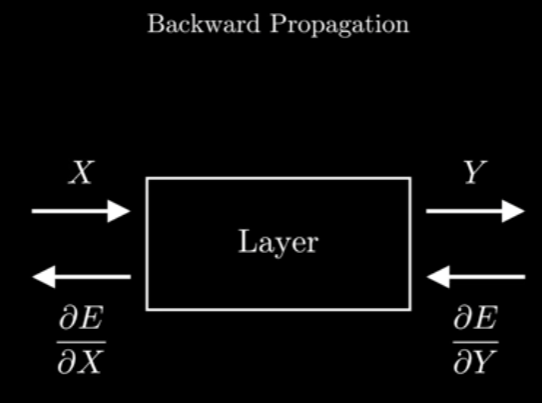
Now, we need to update the parameters, so we give the layer the derivative of error with respect to the output (), and we should give back the derivative of the error respect to the input ().
Main Architecrture:
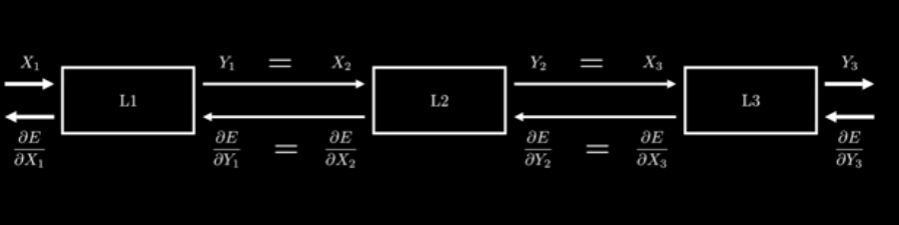
So, most layers are sequential, meaning their output is the input for the next one, that is also why we need the layer to return the derivative of the error with respect to their input () since it will be the same and correlated to the previous layer, that way every layer is connected and able to update its parameters.
Dense Layer:
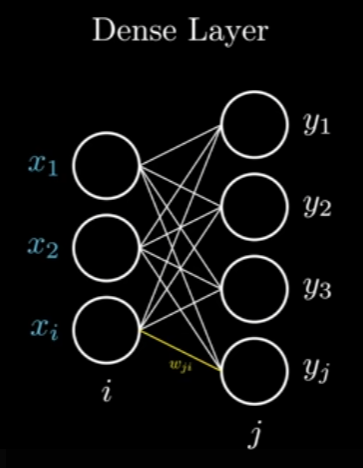
This is the representation of the Dense Layer, which is just a way of calling a full connected layer, layers that are connected to every input, in this example, we have 3 inputs () and 4 “neurons” () resulting in 4 outputs (), each line here is represented as the weight that connects the input and layer ().
Math:
Forward Propagation of the Dense Layer:
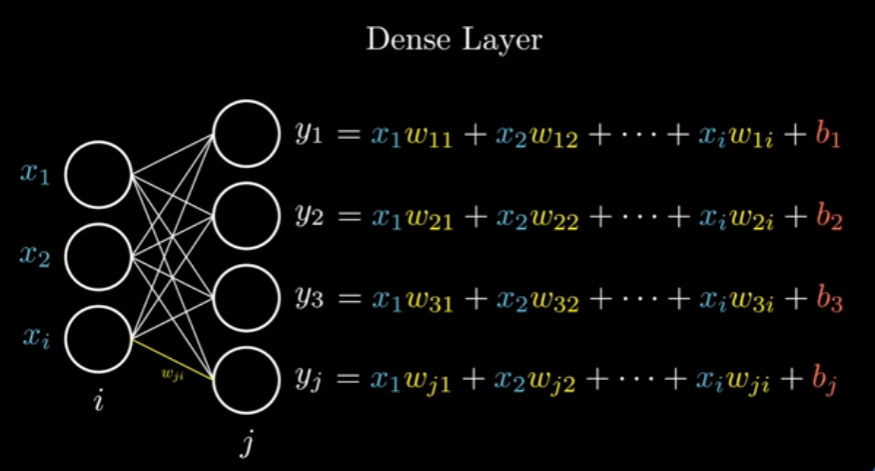
So, every output () represents that equation, but this is long and hard to code, so we instead use a matrix format to do all these operation:
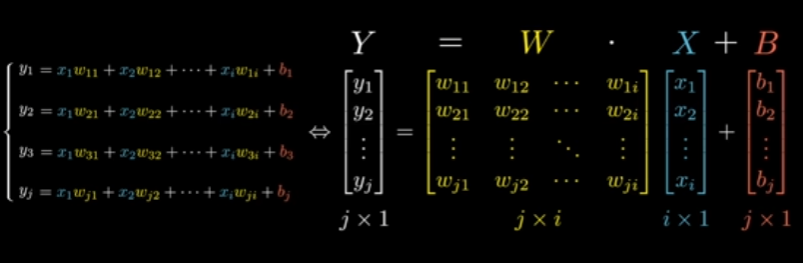
All those equations turn into blocks basically, and easier to visualize and operates with. Doing this we actually get a simpler equation: .
Yes, this is the same as:
= weights
= inputs
= biases
= outputs
Dense Layer Back Propagation:
Skipping directly to the formulas (hope that is okay) we first needed to find , , and .
= derivative of the Error with respect to weights.
= derivative of the Error with respect to the biases.
= derivative of the Error with respect to the input.
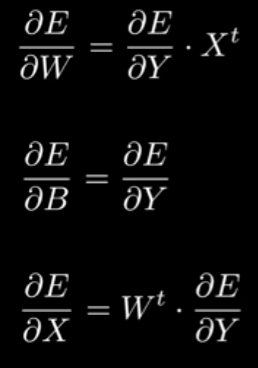
We get these as our equations for each derivative that we needed!
Activation Layer:
An activation layer basically passes or makes sure to pass the input through an “activation function” and makes sure the input is the same shape for the output and vice-versa, therefore every layer’s input/output has the same shape.
Activation Foward Propagation:
Activation function:
Activation Layer Back Propagation:
For this we need to find the derivative of the error with respect to ().

Activation Back Propagation formula:
Using ONE activation function:
To make it clear, there are multiple activation functions, that’s why we simply put as a function and not a real function, because there are many to choose from, in this case, we are gonna use the Hyperbolic Tangent Activation.
Hyperbolic Tangent Equation:
Hyperbolic Tangent Prime: (all we need is the prime of this function!)
The most common activation function is ReLU, which works well with PyTorch and for most cases. Without an activation function, no matter how many layers you stack, the whole network is equivalent to a single linear equation, basically just a flat line. Activation functions introduce a bend, which is what allows the network to learn curved and more complex relationships in data. Necessary for more complex problems such as image recognition and language understanding.
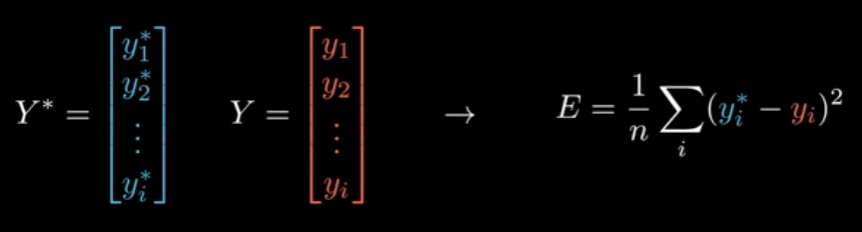
Mean Squared Error:
So we need to find the error, meaning the difference from all the actual outputs () from our desired outputs (), basically calculating how far the actual predictions were from our desired answers = Error.
As we know the layers get the from the next layer but what happens with the last layer? Now that we define what is , we need to pass it to the last layer to find its derivative with respect to Y (the last layer output). Giving us this equation:
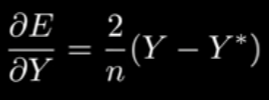
Just like activation functions, there is multiple ways of calculating the error depending of what type of problem are you are trying to solve. But the root is the same, your model gives a prediction, you have a desired answer, find the difference between these two.
Updating Weights
Once we have all the gradients of our weights with respect to the Error, we can update them by a small “step”. This is called the Learning Rate (), which is a hyperparameter, meaning it doesn’t get updated as the weights or biases. Usually the learning rate is declared to be 0.01, 0.001 or less. I won’t get into details about what happens when its too big or too small. But just know is a parameter you choose and most often will have to tweak a bit during training.
To update the weights, we simply subtract the original weight with the product of the derivative of the error with respect to the weight times the learning rate.
Updating weights formula:
Then the whole process repeats this again for a number of epochs. And that’s it!
Neural Networks Explained!
Code Implementation from Scratch:
Layer
class Layer:
def __init__(self):
self.input = None
self.output = None
def forward(self, input):
pass
def backward(self, output_gradient, learning_rate):
pass
Dense Layer
class Dense(Layer):
def __init__(self, input_size, output_size):
self.weights = np.random.randn(output_size, input_size)
self.bias = np.random.randn(output_size, 1)
def forward(self, input):
self.input = input
return np.dot(self.weights, self.input) + self.bias
def backward(self, output_gradient, learning_rate):
weights_gradient = np.dot(output_gradient, self.input.T)
self.weights -= learning_rate * weights_gradient
self.bias -= learning_rate * output_gradient
return np.dot(self.weights.T, output_gradient)
Activation Layer
class Activation(Layer):
def __init__(self, activation, activation_prime):
self.activation = activation
self.activation_prime = activation_prime
def forward(self, input):
self.input = input
return self.activation(self.input)
def backward(self, output_gradient, learning_rate):
return np.multiply(output_gradient, self.activation_prime(self.input))
Hyperbolic Tangent (Activation Function)
class Tanh(Activation):
def __init__(self):
tanh = lambda x: np.tanh(x)
tanh_prime = lambda x: 1 - np.tanh(x) ** 2
super().__init__(tanh, tanh_prime)
Mean Squared Error
import numpy as np
def mse(y_true, y_pred):
return np.mean(np.power(y_true - y_pred, 2))
def mse_prime(y_true, y_pred):
return 2 * (y_pred - y_true) / np.size(y_true)
I wanna be a 7 foot zombie, the pay is low but I gotta do something