Convolutional Neural Network (CNN) + Mathematical Intuition
These are actually notes I had while I was just starting to study ML and Deep Learning, this time: Convolutions!
They are for me very abstract, and I often forget how they actually work. So just like how I did with my post about Neural Networks, I decided to turn this also into a blog post! With the hope to… I guess demonstrate my understanding and possibly help anyone who might read this :)
Thank you.
What is a Convolution Neural Network for?
Convolutional Neural Network (CNN) is a type of Neural Network, and is used mostly for image processing and classification, is basically used to detect patterns in images. Therefore can classify, detect, etc.
For a better understanding and possible review of this topic, watch this video: Convolutional Neural Network from Scratch | Mathematics & Python Code
Respectively credits to The Independent Code youtube channel and github repo for such a great video and code examples.
Math:
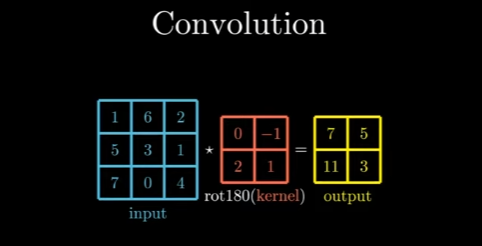
Cross-Correlation Operation:
To understand convolution we need to understand Cross-Correlation. In basic words, is sliding element-wise dot product. Or a sliding window algorithm. (Never thought Data Structures and its algorithms were gonna be useful here).
We Have:
= Input
= Kernel / Filter
= Output
To know the output shape we can calculate it with this equation:
For example:
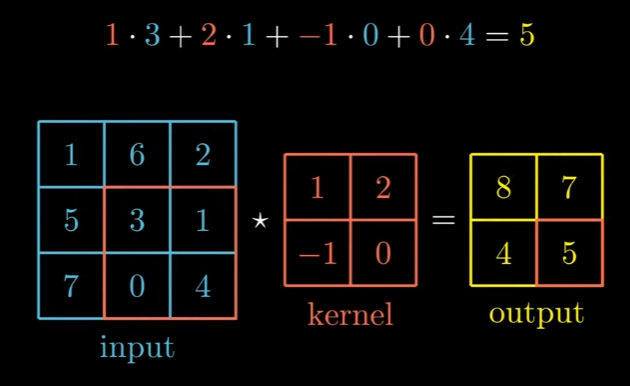
Convolution Operation:
So where the hell is convolution? Convolution is the cross-correlation with the kernel flipped! (both horizontally and vertically). Here we are using rotation 180 degrees, that is the same, but only in 2D matrixes.

Convolutional Equation:
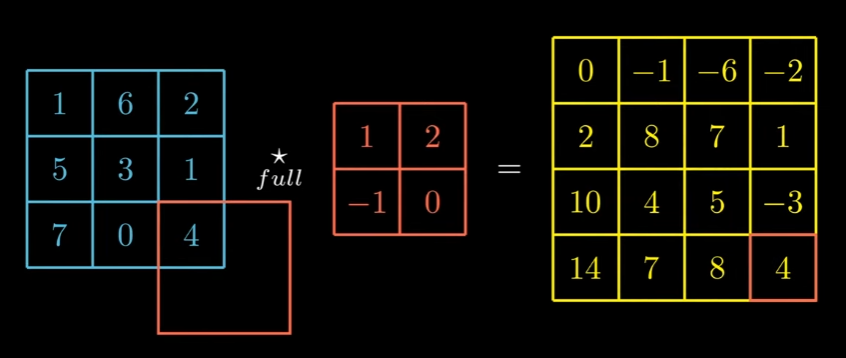
Full Correlation:
We also have full correlation, which is basically multiplying the kernel to the input with every singular point, and sliding one by one. In other words “in this mode, we start computing the product (output) as soon as there is an intersection between the kernel and the input”. This also generates a much bigger output in shape.
Convolutional Layer:
Forward Propagation:
The convolution layer consists of a certain depth in the input, the kernels must be the same size as the input depth and each kernel will be having a bias. This will result in an output, with a depth of # of kernels, e.g. 2 kernels → 2 outputs.
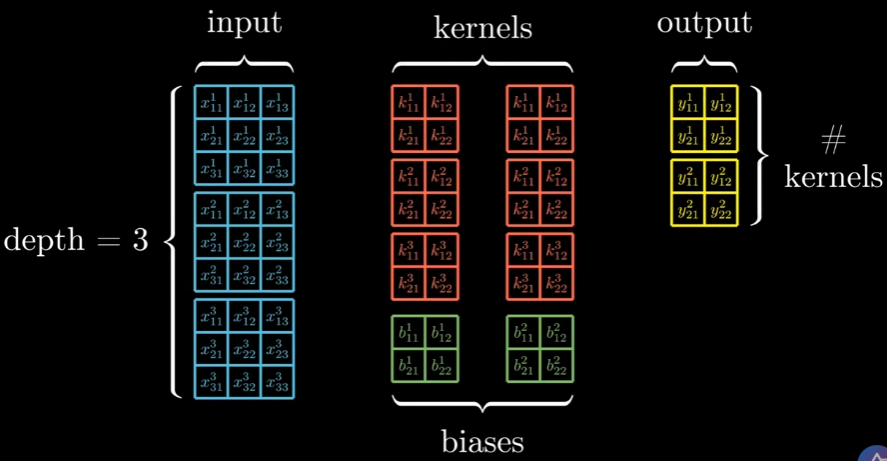
So operation would look something like this: As we can see we do cross-correlation with the 3 kernels with the 3 inputs plus the bias of each kernel, resulting in our first output!
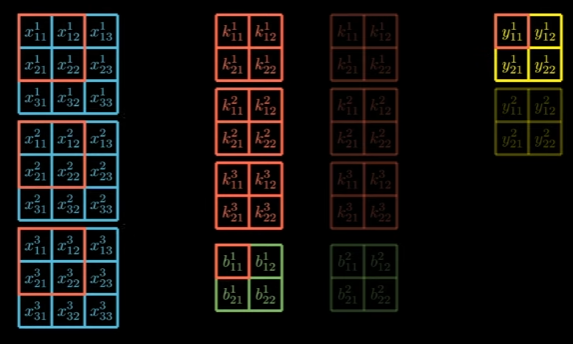
But let’s give a simpler notation to visualize better:

So as we see, we could say:
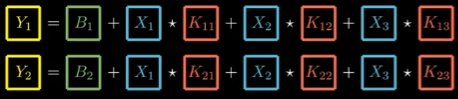
Since our depth could be bigger and we could have as many inputs + their kernel, we could write this as this equation:
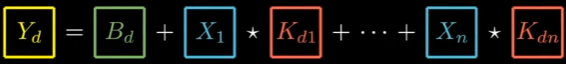
So, in fact, this is the Foward Propagation for the Convolution Layer!
REAL Equation:
Back Propagation:
Just like every backpropagation case, we need to find the derivative of the error with respect to the last output (), so we can update the biases and the kernels (this makes sense because there is no “weights”, instead is a kernel, so you could think kernels = weights).
For this we need to compute two main things: The derivative of error (E) with respect to the parameters (biases and kernels) and the derivative of error with respect to the input (X).
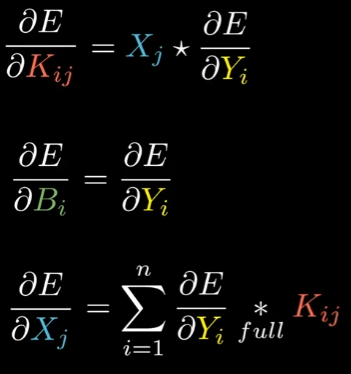
Derivative of the error with respect to the kernels ():
Derivative of the error with respect to the biases ():
Derivative of the error with respect to the input ():
MaxPooling
So after the convolutional layer gives us our new “feature map”, basically the output, we usually want to reduce their size. And that’s what MaxPooling does!
This is because images are usually very large in size. eg. (1080 x 1080 pixels)
The idea here is simple, same with correlation, we slide a small window over the image and at every position, we keep the largest value and throw everything else away.
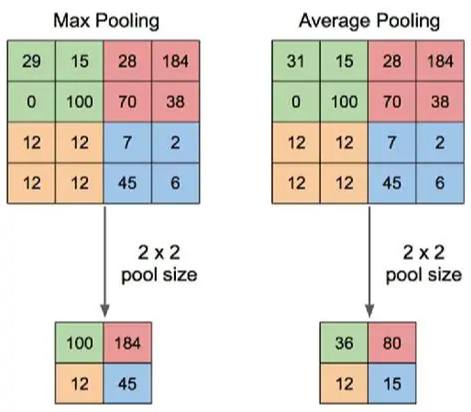
Here we can see two versions, MaxPooling to only keep the largest value, and AveragePooling, where we take the average of all the values from the window.
Stride
Up until now we have been assuming the kernel / filter moves exactly one step at a time, that would be a stride of 1. But we can set stride to be any number we want our kernel to jump each time through the image.
With stride, the output shape formula becomes:
A larger stride means a smaller output and less computation, but you would lose also some spatial detail since the kernel overlaps less. Stride 2 is a common choice when we want to downsample without adding a maxpooling.
Padding
But we have a problem, Convolution reduces our size (depending how big we set the kernel to be and how much stride we set), and MaxPooling also reduces our size. If we want to keep our outputs the same size, we can add zeros around the borders of the input before doing cross-correlation, this is what padding means.
P = padding (Number of zeros rows/columns added to each side)
With padding, the full output shape formula becomes:
Padding is also useful when we want to detect corners, which is usually the part it gets less attention by the convolution.
Code from Scratch:
Convolution:
No stride included, meaning stride is 1.
class Convolution(Layer):
def __init__(self, input_shape, kernel_size, depth, padding=0):
input_depth, input_height, input_width = input_shape
self.depth = depth
self.padding = padding
self.input_shape = input_shape
self.input_depth = input_depth
output_height = input_height + 2 * padding - kernel_size + 1
output_width = input_width + 2 * padding - kernel_size + 1
self.output_shape = (depth, output_height, output_width)
self.kernels_shape = (depth, input_depth, kernel_size, kernel_size)
self.fan_in = input_depth * kernel_size * kernel_size
self.kernels = np.random.randn(*self.kernels_shape) * np.sqrt(2 / self.fan_in)
self.biases = np.zeros(self.output_shape)
def forward(self, input):
self.input = input
self.output = np.copy(self.biases)
# Padding
if self.padding > 0:
self.padded_input = np.pad(input, ((0, 0), (self.padding, self.padding), (self.padding, self.padding)), mode='constant')
else:
self.padded_input = input
for i in range(self.depth):
for j in range(self.input_depth):
self.output[i] += signal.correlate2d(self.padded_input[j], self.kernels[i, j], mode='valid')
return self.output
def backward(self, output_gradient, learning_rate):
kernels_gradient = np.zeros(self.kernels_shape)
input_gradient = np.zeros(self.input_shape)
for i in range(self.depth):
for j in range(self.input_depth):
kernels_gradient[i, j] = signal.correlate2d(self.padded_input[j], output_gradient[i], mode='valid')
full_grad = signal.convolve2d(output_gradient[i], self.kernels[i, j], mode='full')
if self.padding > 0:
full_grad = full_grad[self.padding:-self.padding, self.padding:-self.padding]
input_gradient[j] += full_grad
self.kernels -= learning_rate * kernels_gradient
self.biases -= learning_rate * output_gradient
return input_gradient
MaxPooling:
class MaxPooling(Layer):
def __init__(self, stride=2):
self.stride = stride
def forward(self, input):
self.input = input
depth, height, width = input.shape
output_h = height // self.stride
output_w = width // self.stride
self.output = np.zeros((depth, output_h, output_w))
for d in range(depth):
for i in range(output_h):
for j in range(output_w):
region = input[
d,
i * self.stride: (i + 1) * self.stride,
j * self.stride: (j + 1) * self.stride
]
self.output[d, i, j] = np.max(region)
return self.output
def backward(self, output_gradient, learning_rate):
input_gradient = np.zeros(self.input.shape)
depth, output_h, output_w = output_gradient.shape
for d in range(depth):
for i in range(output_h):
for j in range(output_w):
region = self.input[
d,
i * self.stride: (i + 1) * self.stride,
j * self.stride: (j + 1) * self.stride
]
mask = (region == np.max(region))
input_gradient[
d,
i * self.stride: (i + 1) * self.stride,
j * self.stride: (j + 1) * self.stride
] += output_gradient[d, i, j] * mask
return input_gradient
Some things are flawed by design... but I am fine